
|
||||

 Contents
Contents
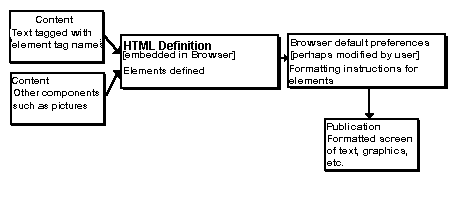
The final formatted appearance of the document is a combination of the author's functional description of its elements together with the interpretation made by the browser package (as modified by the user's preferences)
In HTML the author specifies that an element is one of a set of pre-defined types, such as Sub-Head No3 or List Item, and a definition stored in the browser software specifies the visual interpretation of this type. It is thus a system for specifying the semantic structure of the document, albeit crudely, rather than its mere appearance. The author specifies the function of an element and the browser software applies an appropriate format.
The core of an HTML document is text, of two kinds: text which is to be shown to the end-user and that which instructs the browser software how to behave. In appearance and function it therefore resembles old- fashioned word-processing and print-specification files in which textual codes tags' enclosed in angle brackets are visibly embedded, and which are capable of turning on and off the various styles. The stream of text in the HTML file is split by the browser package into its two components, resulting in a display where only the content-text is visible, but its appearance and behaviour have been dictated by the now invisible tags.
Word-processing packages use codes (usually concealed from both author and reader) to give visual styles to elements of the document. For example a subhead might be in 14pt Baskerville Italic. HTML avoids this specific visual formatting.
When a browser package opens an HTML file (whether locally from a disc or over a network), it reads the content-text and tag-text as a continuous stream. The tags are indicated to the browser by angle-brackets (< and >).
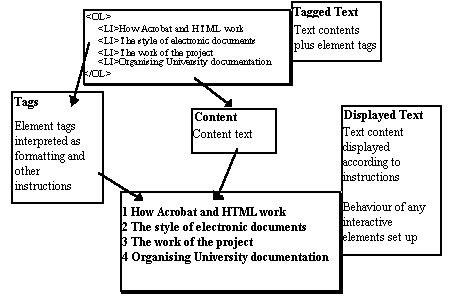
The tag-markers < and > ensure that the tags are split off from the content text by the Browser. The tags are interpreted as instructions for formatting, interaction etc, while the content text is displayed to the user
For each element of the content, such as a headline, there will normally be a start-tag and an end-tag (eg. <H1>My headline</H1>) so the parsing process is quite simple. On finding a start tag, the browser sets the type size, weight, indentation etc. to that specified for this type of element. On finding an end-tag, it turns it off again (usually returning to the default specification for body-text, though it is unwise to assume this).
If the element is a link to another document, then the browser software can interpret mouse-clicks on that word or phrase as an instruction to display the specified document, to jump' to that document. If an element calls for the display of another media type, this is then handled in an appropriate way by the browser.
A significant outcome of this empowerment of the user in relation to the document's appearance is that for those users who are visually impaired or are struggling against adverse viewing conditions, it is a simple matter to set the type styles used by the browser to more acceptable sizes.
This automation deprives graphic designers of many opportunities to exercise the subtleties to which they are accustomed, but it makes for an efficient production-line approach to the laying out of large quantities of text.
This approach has a lot to offer Education, where many documents share a common structure, for example course module descriptions. Fully marked-up text can be automatically generated from a database which stores every module description. For such documents which share a structure and to a large extent a style across a whole institution, there is very little to be said for everyone creating their own formatted text. In addition, where cross- reference to a common text is required, for example to the attendance regulations, the hypertext link which invokes this single document can be inserted automatically in every module document. If it is altered, it appears in its new form in every single location where it is cited.
Contents
Graphics Multimedia Virtual Environments Visualisation Contents