|
||||

 [Top]
[Top]Review of Visualisation Systems
Fuller descriptions of the principles of data models are given elsewhere ([11],[63],[18],[17]). Here we confine ourselves to a few practical issues and describe how these are addressed in the visualization systems. We cover type, dimensions and organization of the data.
The scientific investigator who needs visualization is concerned with the values of certain properties defined on a grid.
In simple cases there is a single property, but in many cases the investigator is interested in several properties on the same grid. So the fluid dynamics expert could be concerned with pressure, temperature and flow. This is the dependent data which may represent measurements or the results of computations. In some problems there could be many dependent variables.
Visualization systems normally deal with discrete data. Although it is possible to deal directly with mathematical expressions, this is a subject not well dealt with in general purpose visualization systems. Even if the investigator's mathematical model involves a continuum, for computation or measurement reasons the data has usually been sampled. Hence we refer to a grid, which consists of a set of nodes - the independent data - used to define where the dependent data is sampled.
The coordinate system of the grid often consists of cartesian spatial dimensions and also time. A collection of flow data is a good example of this, using either 2 or 3 spatial dimensions.
However the coordinate system need be neither cartesian nor spatial. Chemical reaction rates may depend on the concentration of the constituent substances, the presence or absence of a catalyst and other quantities such as temperature. For the investigator, these are the independent variables and the values of those quantities, at which chemical reaction rates have been measured or calculated, represent a grid. For some problems, there could be many independent variables.
Another improvement is the facility to extend this base data structure with user defined fields. For example you could add patient attribute information to image scans and the modules within AVS would still recognise and process this extended data type as an image.
Other features include support for cylindrical, polar and spherical coordinate systems and the provision for users to specify NULL (undefined) data values. These underlying data types will also be supported by the visualization modules in AVS6.
With AVS6, there will be a number of new features to improve the handling of large data sets. These features include:
This generated the following general array format header:
file =./hipiph.ascii
The import module converts the data into DX objects, in this case, a Field with 5 components:
object 1 class array type float rank 0 items 262144 msb ieee data 0
It is possible to define a DX header to import node and or cell-based data into DX. For example the following lines have been extracted from the standard example dataset in /usr/lpp/dx/samples/data/irregular.dx data file:
# The irregular positions, which are 24 three-dimensional points.
When using DX it is also possible to set a valid range of values for use by the autocolour/autogreyscale and specify colours to be used for out of range data (this could be used to highlight unsuspected invalid data). Also the Include module can aid the viewing of invalid data and data ranges. This module allows the user to select only those points which lie within or outside a given range. Non selected points can be marked as invalid (Cull).
Although facilities for importing data by using a header description are very powerful in Data Explorer, it is also possible to generate filters (e.g. the FLUENT filter in the public domain) or import modules (e.g. the PHOENICS import module from the public domain). To develop code to import data both as filters and modules see Chapter 6, "Modules that Import Data", and Chapter 10, "The Data Model", of the Programmers Reference manual.
This section outlines the basic range of data types which are provided for importing the following classes of data. The Explorer data types covered are:-
The values of nDim and dims must be the same for each section. There are 5 primitive types:- byte, short, long, float and double.
Lattices have 3 coordinate types:-
A number of chemistry modules have been written for IRIS Explorer at Imperial College; these are bundled with version 2.2 in the unsupported modules category. These include modules for reading data from a variety of chemistry packages (see section 4.4.1), for the creation of geometry representing molecules as ball and stick and ribbon constructions, and for the animation of molecular vibration modes.
Geometry is read into and written out of IRIS Explorer as an Inventor object, which makes it available to other Inventor applications such as SGI's Showcase presentation package. The Open Inventor file format is being promulgated by SGI as a de-facto standard for 3D scenes, and the number of Inventor applications, readers and translators is apparently on the increase.
Once the user has defined the data type using the ETL, IRIS Explorer compiles it. This consists of the automatic translation of the ETL file into C and creates a library of accessor functions for the different components of the type, together with the appropriate header files. Information about the new type is automatically picked up by tools such as the Module Builder (used in the creation of new modules - see below) and the Map Editor (used in the creation of new applications). The user can then write their own modules to process data using the new type, manipulated via the new API which has been automatically generated by IRIS Explorer in the compilation of the type.
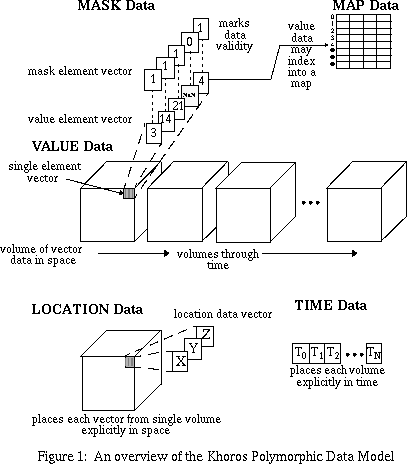
The value segment consists of a time-series of volumes where each volume is composed of element vectors. Each element vector is composed of a number of value points. The size of the value segment is determined by the width, height, and depth of the volume, by the number of volumes through time, and by the number of points in the element vector. This makes the value segment, and the polymorphic data model, inherently five-dimensional.
The location segment consists of a volume of location vectors. The width, height, and depth of the volume are identical to the volume size of the value segment. Different location grid types are also supported. A curvilinear grid allows for explicit locations to be specified for each vector in the value data. A rectilinear grid allows for explicit locations to be given for the width, height, and depth axes. A uniform grid allows for explicit location corner markers to be specified.
The time segment consists of a linear array of timestamps. The number of timestamps matches the time size of the value segment.
The map segment consists of a number of width-height planes. The values from the value segment map into the map height indices. The map vector runs along the map width. A simple map would consist of just a single width-height plane; a more complicated map would have a width-height plane for every depth, time, and element plane in the value segment. This provides a great deal of mapping flexibility. For example, every plane in a volume or every image in an animation could have a separate map.
The geometry data model is centered around a primitive list. This list is able to store any combination of geometric primitives such as spheres or polylines. Each geometric primitive consists one or more different types of data, suchas location data and color data. The types of data required depend on the primitive; all primitives have location and most have color while only some have radii or normals. Most data is explicitly provided, although colors may be provided indirectly via a colourmap. Quadmesh and octmesh primitives, which are not illustrated here, are also available. These mesh primitives are overlaid on top of the polymorphic data model. Thus, from the point of view of the polymorphic data model, a quadmesh will appear to be an image, and an octmesh will appear to be a volume.
The polymorphic data model allows an explicit location to be assigned to every data vector in the Value segment, thus sparsely distributed node data can be represented. Connectivity between the nodes can be specified only through the implicit organization of the Value data. There is no support for explicit connectivity between arbitrary nodes.
3.2.1 General introduction
After importing, the visualization system uses its native form to manipulate a dataset - the external form is not used except to access and import the original data again. The capabilities of a visualization system are limited by the data model offered by this native form. A very powerful data model allows a wide range of visualization possibilities. However it is also possible for this potential not to be realised either in the supported product or by 3rd party software - we review the actual coverage in the sections on Algorithms and Presentation.3.2.2 AVS
This section outlines the basic range of data types which are provided for importing the following classes of data. The information provided is correct for the current version of AVS (AVS5) but an additional section has been added to provide details on the changes that will be provided by the next release of AVS (AVS6) in early 1995. AVS5 provides a number of datatypes:
Simple data types (character strings, integers, real, boolean)
The simple scalar types (character strings, integers, real, boolean) are all supported as AVS datatypes.General 1D/2D/3D arrays of data
The field datatype allows the importing of general arrays of data elements (N dimensional array of M elements). The datatype allows the dimensions of the arrays to be described with an optional mapping/transformation being applied to the data elements of the array as they were being imported. These mapping types were split into three distinct types:
Node and Cell based data
The Unstructured Cell Data (UCD) type is aimed at providing support for associating data with discrete geometric structures. The data type consists of nodes and cells to form the overall UCD structure:
Data can then be optionally associated at node positions, part way along a connection between two nodes (mid-edge) or with a complete cell or UCD structure.Geometric data
The AVS Geometry data type is provided to support the display of 2D/3D graphical objects. The primitive datatypes provided are: disjoint lines, triangle and quadrilateral meshes, polyhedron definitions and spheres. There is also support for the definition of light sources, texture mapping and control over the camera parameters to perform clipping, depth cueing and perspective viewing of scenes.Chemistry application data
The Molecule Data Type (MDT) is provided to support chemistry applications and consists of a number of objects arranged in a hierarchical structure:
Colourmaps
The AVS colourmap data type is an arbitrary sized one-dimensional array of 4D vectors. The vector components are normalised floating point values which represent hue, saturation, brightness and opacity.User defined data
The AVS system provides a variant of defining structures in the C programming language which encapsulates a number of the scalar data types into a user defined structure. The structure can also contain arrays of these scalar types.Errors and undefined values
Currently there is no real support for errors or undefined values but this is provided for in AVS6.AVS6
This section details the changes to the data types which will appear with the release of AVS6 in Q2 1995. In AVS5 different data types were required for different classes of data (i.e., 2/3D data, finite elements, geometric). AVS6 now has one unified data type which can be used to represent these classes of data within the same data structure. This removes the need for different visualization modules to perform the same function on different types of data e.g., there is now only one isosurface module for both field and unstructured cell data.
3.2.3 IBM Data Explorer
Data Explorer presents a unified data model based on the concept of a field. This concept brings together the grid positions used to define where the data is sampled, the connectivity and the property data. From the point of view of the user, a module may be defined on any kind of data where it is reasonable to do so - there is no artificial distinction between types of data. Simple data types (character strings, integers, real, boolean)
DX does not really treat these as data types. Some modules do process all these data types - as standard C items - but are generally parameters to determine how to process data. A DX object can be a string, but better support is provided for strings and numbers that are associated attributes of a more complicated data structure (e.g. to associate the data with a name or number).General 1D/2D/3D arrays of data
The easiest way to import array data into DX is to use the prompter tool. Figure 6 shows the interface to import an ascii file containing data values on a uniform 3D grid. The data file consists of data values only, and has a float value per line.
grid = 64 x 64 x 64
format = ascii
interleaving = series-vector
majority = row
field = hipip
structure = scalar
type = float
dependency = positions
positions = 0, 1, 0, 1, 0, 1
end
which converts to the following DX format when imported with the import module and exported with the export module (the actual data is now binary and not shown here):
attribute "dep" string "positions"
#
object 2 class gridpositions counts 64 64 64
origin 0 0 0
delta 1 0 0
delta 0 1 0
delta 0 0 1
attribute "dep" string "positions"
#
object 3 class gridconnections counts 64 64 64
attribute "element type" string "cubes"
attribute "ref" string "positions"
#
object "hipip" class field
component "data" value 1
component "positions" value 2
component "connections" value 3
attribute "name" string "hipip"
#
end
Node and Cell based data
Both node and cell based data are supported. To define node data, state the data is dependent ("dep") on the positions and for cell based say it is dependent on connections. Current cell types include: line, triangle, tetrahedron and cube (the latter is a general purpose shape defined by 8 vertices). Currently no mid edge data is supported.
object 1 class array type float rank 1 shape 3 items 24 data follows
0 0 0
0 0 1
0 0 2
0 2 0
0 2 1
0 2 2
1 0.841471 0
.............
3 2.14112 2
# The irregular connections, which are 30 tetrahedra
object 2 class array type int rank 1 shape 4 items 30 data follows
10 3 4 1
3 10 9 6
10 1 7 6
.........
17 20 23 22
attribute "element type" string "tetrahedra"
attribute "ref" string "positions"
# The data, which is a one-to-one correspondence with the positions
object 3 class array type float rank 0 items 24 data follows
1 3.4 5 2 3.4
5.1 0.3 4.5 1 2.3
4.1 2.1 6 8 9.1
2.3 4.5 5 3 4.3
1.2 1.2 3 3.2
attribute "dep" string "positions"
# the field, with three components: "positions", "connections", and # "data"
object "irregular positions irregular connections" class field
component "positions" value 1
component "connections" value 2
component "data" value 3
end
In this example the data is included with the description but does not have to be.User defined data
DX has a rich collection of data objects, it is also easy for the user to group a number of objects into a more complex structure (although the description header may be difficult to read).Errors and undefined values
It is possible to specify the data is invalid, by including a component invalid positions which lists the locations, or invalid components to list invalid cells (where cells can be any cell, e.g. an FE cell or a cell from a uniform grid). This means holes can appear in both regular and irregular grids, or allows the user to define regions where another grid applies in a particular region (e.g. to replace parts of a grid with areas of greater detail). The standard example network /usr/lpp/dx/samples/programs/InvalidData.net shows that invalid data is not rendered - e.g. holes appear in the shaded object, contour lines do not pass through invalid points and streamlines stop at invalid points. Any comments
DX also has good support for series of data, such as time series. It can also handle the B-rep model for CSG as it is possible to have faces, loops and edges components in an object (e.g. the CSG examples in the public domain).3.2.4 IRIS Explorer
IRIS Explorer - like AVS - also presents a distinction between major data types. As well as geometry, IRIS Explorer provides lattices, pyramids and parameters.
Simple data types (character strings, integers, real, boolean)
The Parameter data type handles all of these explicitly, with the exception of boolean (although those values can of course be handled as some other data type).General multidimensional arrays of data
This form of data is handled by Explorer's Lattice data type. The Lattice is sub-divided into 3 parts:-
Colour maps are just specific instances of a 1D uniform lattice with either 1 data variable (grey scale), 3 data variables (RGB) or 4 data variables (RGB & opacity).Node and Cell based data
The Explorer Pyramid data type holds two types of data: irregular or unstructured data and molecular modeling data. A pyramid consists of 3 main parts:
Irregular or Unstructured Data: In IRIS Explorer, the Pyramid data type is primarily used for finite element modelling and creating irregular grids and most Explorer pyramid modules handle only this kind of data. The basic layers to create a Tetrahedral grid include:
Molecular Modeling
Chemistry pyramids are used to construct objects according to information pertaining to molecule structures. This pyramid structure is more narrowly defined than that for finite elements and represents (in the 3D layer, layer 2) not a volume, but a ball-and-stick construction. There are a number of modules associated with this type such as BallStick which takes a molecule pyramid and outputs it, in Geometry, as a ball and stick construction, and ReadPDB which links in to the Brookhaven Protein DataBase and can search for named molecules and builds Chemistry Pyramids. Geometry data type
As noted above in section 3.4.7, geometry in IRIS Explorer is implemented using Inventor, an object-oriented 3D toolkit. Geometry objects which can be created via the IRIS Explorer geometry API include points, lines, polygons, spheres, cones, cylinders, triangle meshes, NURBS patches, octree volumes, and text; this interface also offers control over colours, lighting and geometric transformations. It is possible to also create and manipulate the geometry via the Inventor API.Pick Data
This is a specialised data type that is used only in 2D and 3D modules. It is used to enable the user to pick, or select, a particular location in an image (2D) or rendering (3D) module display window and obtain information about it. For example, you may want to query part of a picture of an isosurface. You could find out the coordinates of a spot on the surface or the data value at that point. It is also possible to use the pick data type to create an object or move an existing object to a new location in a rendering module display window. As the user clicks on the position in the window the information goes to an upstream module which creates the new geometry and sends it to the Render module.User defined data
IRIS Explorer provides a language, called the Explorer Typing Language (ETL) which can be used to build new user-defined data types that can be passed between modules in the same way as other IRIS Explorer data types. ETL was used to create the standard Explorer root types such as Lattice and Pyramid etc., which contain subtypes such as cxData and cxCoord. A user-defined root type can reference these Explorer subtypes in its definition. ETL is syntacticly very similar to C.Errors and undefined values
Having read in an Explorer Lattice there are several ways to deal with erroneous values. Using ScaleLatNode it is possible to define a min and max for the data and then either Clamp, stretch or threshold the erroneous values. Clamping fixes the value to either the min or the max value, stretching rescales the data to fit the parameter min and max and thresholding produces a binary array where 1.0 is inserted for a correct value and 0.0 for an error. This can be used later to take different courses of actions for correct and error values.Value Segment
The value data segment is the primary storage segment in the polymorphic data model. Most of the data manipulation routines are specifically geared toward processing the data stored in this segment. In an imaging context, the individual pixel RGB values would be stored in here. In a signal context, regularly sampled signal amplitudes would be stored here.Location Segment
The value points in the value segment are stored implicitly in a regularly gridded fashion. Explicit location information can be added using the location segment. If the value data is irregularly sampled in space, the explicit location of each sample can be stored here. Specifically, the information stored in this segment serves to position each the value data in explicit space. Note that the location data only explicitly positions a single volume; the position then holds for each volume through time.Time Data
Explicit time information can be added using the time segment. If each volume of value data is irregularly sampled in time, an explicit timestamp for each volume can be stored here. This is useful in animations where each frame of the animation occurs at a different time.Mask Data
The mask segment is available for flagging invalid values in the value segment. If a processing routine produces values, such as NaN or Infinity, these values can be flagged in the mask data so that later routines can avoid processing them. A mask point of zero is used to mark invalid value points, while a mask point of one is used to mark valid value points. The mask segment identically mirrors the value segment in size; there is one mask point for each value point.Map Data
In cases where the value data contains redundant vectors that are duplicated in different positions, the map segment may be used. The value vectors are replaced with values which index into the map; the map then contains the actual data vectors. In this sense, the map is an extension of the value segment.Geometry Data Model
The geometry data model supports the storage and retrieval of a number of standard geometric primitives, such as spheres, triangles, and lines. Other non-geometric primitives such as octmeshes and textures are also supported.General 1D/2D/3D Arrays of Data
The polymorphic data model can be used to represent up to five dimensional arrays of data complete with auxiliary information such as explicit location and time data, validity data, and map data.Node and Cell Based Data
Explicit nodes are provided for vertices or cells in the Geometry data model, however the connectivity is implied by the geometry primitive which the data represents. There is no support for arbitrary connectivity.User Defined Data
The data services provides library calls for manipulating a generic abstract data object containing arbitrary segments of any dimensionality. While new data models could be constructed using this, it is not recommended as no existing processing operators would be able to operate on the data. In general, if the data can be expressed in a five-dimensional space, it is best to use the polymorphic data model.Errors and undefined values
The Mask data can be used to specify the validity of the data (undefined data). There is no explicit mention of support for errors within data values but the application could simply allocate a portion of the data vector to support this feature. Even a combination of the mask and value data could be used for indicating if data has an error component associated with it. 3.2.6 PV-WAVE
In principle, PV-WAVE's data model could be as general as its command language. This includes arrays and structures, which in combination allows a very flexible data definition. In practice the data is confined to what can reasonably be handled by the plotting procedures. To give an example, although it is possible to defined unstructured data using PV-WAVE's data types, no procedures to plot such data are available. More detailed information can be found in Chapter 4: Data Import section 4.6.1
Review of Visualisation Systems
[Top]
Generated with CERN WebMaker
Graphics Multimedia Virtual Environments Visualisation Contents