
|
||||
| Also available as an Acrobat File | 

|
|
Parallel Coordinates |
An Investigation of Methods for Visualising Highly Multivariate Datasets4. The Parallel Coordinates Approach to VisualisationIn this final section on approaches to visualising multidimensional data sets, a very different approach is taken. In both of the previous techniques, a point in m-dimensional space was mapped onto a point in 2-dimensional space. In this approach, a point in m-dimensional space is represented as a series of m-1 line segments (Inselberg et al., 1987) in 2-dimensional space. Thus, if the original data observation is written as (x1, x2, ... xm) then, its parallel coordinate representation is the m-1 line segments connecting the points (1,x1), (2,x2), ... (m,xm}. Each set of line segments could be thought of as a ´profile' of a given case. The shape of the segments conveys information about the levels of the m variables. This is illustrated in figure 9. Typically, continuous variables will be standardised before a parallel coordinate plot is drawn.
Figure 9: A Parallel Coordinate Representation of One Case To view an entire m-dimensional data set one simply plots all such profiles on the same graph. This is illustrated in figure 10. For large data sets, the appearance of such a plot appears confusing, but can be used to highlight outliers. However, the real strength of the technique can be seen when subsets of the data are selected, usually on the basis of one particular variable.
To see this, consider figure 11. Here, the subset of the data in the lowest decile of the variable LLTI is shown in black, and the remainder of the dataset in grey. Looking at the relative locations of the black and grey lines shows the distribution of the data values in the subset in relation to the entire data set. Obviously, all of the black lines pass through the lowest section of the LLTI axis. However, looking at the locations of the black lines on the other axes shows whether the low values of this variable tend to be accompanied by any notable distributional patterns in the other variables. From the plot, it may be seen that often there are also low values of DENSITY and UNEMP. Parallel plots may also be used to detect outliers in two dimensions. Again looking at figure 11, there are a few cases in the subset where DENSITY is unusually high, given the low value of LLTI. It is also apparent that this phenomenon does not occur with the variable UNEMP. This technique can also be used, at least sometimes, to detect three-dimensional outliers. For example, the black line joining a high(ish) value of SC1 to a similar value of SPF is unusual: first in a two-dimensional sense because it appears unusual that the two variables both have high values, and second in three dimensions because we can also see that this line is black and therefore associated with the lowest decile of LLTI. Outliers detected in terms of the lines connnecting pairs of axes in the parallel system pose an interesting problem. Although the method provides a striking image of outliers between two variables, it only works if the two variables have neighbouring parallel axes. For m variables, there are only (m-1) such neighbours possible, but there are m(m-1)/2 possible variable pairs. Thus, (m-1)(m-2)/2 pairs cannot be displayed. The problem is similar to the ordering problem in RADVIZ, that is the patterns that parallel coordinate plots yield depend on the ordering of the axes. In this case, there are m! possible orderings, although if we assume that reversing the order of the axes generates equivalent patterns, this leaves m!/2 possibilities. Again, as with RADVIZ, we are left with a combinatorial computational problem. One approach to this might be to maximise the variability of the centre points of lines between pairs of variables. If these are well-separated then this makes patterens or outliers easier to detect. Suppose v1 and v2 are variables with neighbouring axes, then the midpoint on the plot will have a height of (v1 + v2)/2. The horizontal coordinate is not of interest, as it will be fixed for all values of v1 and v2. Suppose also that v1 and v2 are standardised, and so have variance of one. Then, the variance of the height will be 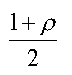
where [rho] the correlation between v1 and v2. If these quantities are added together for each pair of adjacent axes, an index score is created. Choosing a suitable ordering is then a matter of maximising this quantity. In fact, the problem may be simplified by replacing the above expression with [rho], or changed to a minimisation problem by replacing [rho] with 1- [rho]. In fact, this problem is equivalent to the travelling salesman problem. To see this, regard 1-[rho] 's between pairs of variables as lengths of trips between towns, and axis ordering as visit ordering for the towns. Total distance is then equivalent to total 1-[rho] 's, which is minimised in the travelling salesmen problem. A large amount of research into this mathematical problem has been carried out, and, although solutions are possible they require large amounts of computational effort. It is also worth noting that other indices besides the correlation sum could be used to choose an ordering, so that, for example, clustering of centre points into multimodal groups could be rewarded, in a similar manner to projection pursuit. So long as the measure used is a sum of two-way interactions between the variables, the equivalence to the travelling salesman problem applies. |
Graphics Multimedia Virtual Environments Visualisation Contents


