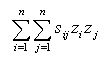|
||||
| Also available as an Acrobat File | 

|
|
The Projection Pursuit |
An Investigation of Methods for Visualising Highly Multivariate Datasets2.3 InterpretationHaving obtained an optimal projection, it is essential that this can be easily interpreted. Since the projection is a linear mapping, interpretation is fairly straighforward. Having optimised in terms of c and d, one may work backwards to obtain a and b. If jth individual elements of these vectors are aj and bj, then a unit change in the jth original variable causes a change (aj, bj) in the projection space. Since the projection is linear, this statement is independent of the values of other variables. Also due to linearity, a change by an amount k in the jth variable leads to a change (kaj, kbj) in the projection space. Using this fact, one can plot the ´change vectors' for a given point in the plot in projection space when each of the initial variables changes by one standard deviation. This is illustrated in figure 4.
Figure 4: Minimised MNND projection of census data - Interpretation Plot This gives some clues as to the variables causing the ´spur' in the projection shown in figure 3. Although a number of possible variable combinations could cause this, figure 4 suggests that very high unemployment levels or low crowding could cause this, perhaps with low levels of the other variables. 2.4 Choice of IAt this point, some further discussion about the choice of the index function, I, might be appropriate. The example above was chosen to maximise clustering in the projected data image. However, other functions could be chosen to reflect other desired properties of the projection. Another important data feature is the presence of outliers. One way of ´rewarding' projections that produce outliers is to negate the previous measure, or equivalently to maximise the MNND subject to the previous constraints. To see this, note that outliers are a long way from their nearest neighbours. When there are a large number of outliers, or one or two very extreme ones, the MNND will tend to be large. The result of this approach is shown in figure 5, together with an interpretation plot in figure 6. The spur feature has now completely disappeared, and the projected points now form a more symmetrical pattern, but a number of outliers are visible in many directions around the outside of the cloud. The interpretation plot should help in identifying the nature of the outliers as in the previous example.
A further possibility is to consider means of highlighting geographical trends. In this case, the idea of ´projection' takes a different form. Here, a one-dimensional projection is used, z say, but the value of this projection is shown on a choropleth map. If this approach is taken, the projection should be chosen to emphasize geographical trends. One way of making this choice is to consider the spatial autocorrelation of the trends. To find trends which vary smoothly over the geographical study area, one needs to maximise the degree of spatial autocorrelation of the index. Similarly, to highlight local differences in data, one needs to minimise the spatial autocorrelation. Each of these goals could be achieved by defining I in terms of spatial autocorrelation. Morans (Moran, 1948} measure of spatial autocorrelation may be written as
where sij is one if zones i and j are neighbours, and zero if they are not. Neighbourhood may be defined in a number of ways. Typically zones are neighbours if they share a common boundary, or if their centroids are less than some distance apart. If the z values are standardised to have variance one and mean zero, then the above expression simplifies to
If we are attempting to maximise or minimise this expression, the denominator may be ignored, since it is a positive constant. Thus, for projection pursuit designed to high geographical relationships, a suitable I is given by
Thus, here the projection pursuit problem can be stated as
since in this case I is simply a quadratic expression, and there is just one constraint, the computational overheads are much lower than for the MNND-based problem. Interpretation of the single-dimensional projection is probably best done by tabulating the elements of a, possibly scaling by the standard deviation of each variable. This shows the degree and direction of change that would be seen in z if a given variable were to increase by one standard deviation. Applying the method to the census data gives the maps in Appendix B, which show indices for maximum and minimum spatial autocorrelation respectively. The coefficients of projection (adjusted for scale) are given in table 1. Here it can be seen that the maximising map mostly picks up an urban/rural trend, whereas more subtle differences are picked out in the minimising map. In particular it highlights the way some nearby rural areas differ. The strongest contributing variables in the maximising case are CROWD, LLTI and UNEMP. It is suggested that this linear combination of variables is perhaps a useful indicator of 'urbanness' in the sense that high values tend to coincide with inner cities and low values with rural areas. On the other hand, the coefficients for the minimising case give a very different index. This index is useful for differentiating between nearby places, and is more strongly influenced by variables that are more spatially variable. A good example is SPF which has a much greater weighting in the minimising index. Although there is no strong geographical trend in the proportion of single parent families, it can be used as a means of differentiating between nearby places. Another variable that does this is CROWD which is possibly a differentiator between affluent and poor rural communities. 2.5 Geographically Weighted RegressionAt this point, another trend-based method of analysis should be considered briefly. This is the method of Geographically Weighted Regression (GWR), see for example Brunsdon et al. (1996). In this approach, a multivariate regression is carried out, but instead of a global model, localised models are fitted around a number of points in the study area. For example, using the LLTI data set from the previous section, a number of sample points in northern England are chosen, and, taking a circle drawn around each point, a ´local' regression is calibrated. Typically, this is a weighted regression, and the weight given to each observation, in this case a Census ward, decays with the distance from the sample point. Thus, eventually, a different regression is calibrated for each sample point. Mapping the way the regression coefficients change for a series of sample points spread throughout the study region shows geographical changes in the relationship between the variables. Typically the sample points are placed on a regular grid, or centred on the areal unit centroids. Note that it does not matter if the circles centred on the points overlap; indeed this allows smoother trends in the regression coefficients to be mapped. Note that this differs from the projection pursuit using Moran's-I in two major ways. First, whereas the projection pursuit method produces just one map, (or two if Moran's I is both minimised and maximised), GWR produces a map for each regression coefficient, plus one for the intercept coefficient. Secondly, project pursuit treats all variables identically, whereas GWR requires that one variable has to be ´singled out' as the dependent variable. A comprehensive example of the technique is given in Brunsdon et al. (1996). Although this method does not fall directly into the projection pursuit category, one way of viewing the regression model is as a ´best fit' linear projection, and this is a useful approach to finding geographical trends in such projections. |
||||||||||||||||||||||||||||
Graphics Multimedia Virtual Environments Visualisation Contents